现在,你只需 5GB 的 VRAM 就可以训练自己的 Qwen2.5(1.5B)推理模型——相比两周前我们发布的 GRPO 版本下降了很多!目前,实现更长的上下文长度是 GRPO 面临的最大挑战之一。我们新推出的 Unsloth Efficient GRPO 算法在使用 减少 90% VRAM 的情况下,实现了 10 倍更长的上下文 相比于其他所有 GRPO 的 LoRA/QLoRA 实现,甚至包括使用 Flash Attention 2 (FA2)的实现。
在使用 TRL + FA2 的 GRPO 设置中,Llama 3.1(8B)在 20K 上下文长度下训练需要 510.8GB 的 VRAM。然而,Unsloth 的 90% VRAM 减少将该需求降低到同样设置下的仅 54.3GB。
试用我们支持 10 倍更长上下文的免费 GRPO 笔记:Llama 3.1(8B)在 Colab 上的实现
我们强烈建议阅读 我们的指南,以了解 GRPO 和奖励函数/验证器的一切信息。
查看我们的 GRPO 笔记,其中包括诸如 Phi-4 模型的其他模型查看此处。
为长上下文提供 90% 更少的 VRAM
当您使用 Unsloth 进行 GRPO 时,通过使用多个技巧,我们巧妙地将 VRAM 使用量减少了 90%以上,与标准实现使用 Flash Attention 2 相比!以 20K 上下文长度为例,每个提示生成 8 次时,Unsloth 仅使用 54.3GB 的 VRAM 用于 Llama 3.1 8B,而标准实现需要 510.8GB (Unsloth 减少 90%)。
- 我们的新内存高效线性算法用于 GRPO,将内存使用量减少了 8 倍或更多。这减少了 68.5GB 的内存 ,通过 torch.compile for num_generations = 8 和 20K 上下文长度的帮助,速度实际上更快。
- 我们利用我们之前发布的智能 Unsloth gradient checkpointing 算法。它智能地将中间激活异步卸载到系统 RAM,而仅慢 1%。这减少了惊人的 372GB VRAM ,因为我们需要 num_generations = 8。通过中间梯度积累,我们可以进一步减少这个内存使用量。
- Unsloth 还使用与底层推理引擎(vLLM)相同的 GPU / CUDA 内存空间,这减少了 16GB 的 VRAM。
| 指标 | 🦥 Unsloth | TRL + FA2 |
|---|---|---|
| 训练内存成本 (GB) | 42GB | 414GB |
| GRPO 内存成本 (GB) | 9.8GB | 78.3GB |
| 推理成本 (GB) | 0GB | 16GB |
| 20K 上下文的推理 KV 缓存 (GB) | 2.5GB | 2.5GB |
| 总内存使用 | 54.3GB (减少 90%) | 510.8GB |
在典型的标准 GRPO 实现中,你需要创建大小为 (8, 20K) 的 2 个 logits 来计算 GRPO 损失。这需要 2 * 2 bytes * 8 (num generations) * 20K (context length) * 128256 (vocabulary size) = 78.3GB 的 VRAM。Unsloth 减少了长期上下文 GRPO 的 8 倍内存使用,因此我们仅需额外 9.8GB 额外的 VRAM 用于 20K 上下文长度!
我们还需要从 KV 缓存以 16bit 计算。Llama 3.1 8B 有 32 层,且 K 和 V 均为 1024。对于 20K 上下文长度,计算的内存使用量为 2 * 2 bytes * 32 层 * 20K 上下文长度 * 1024 = 2.5GB 每个批次。我们将 vLLM 的批量大小设置为 8,但我们将其保留为 1,以便我们的计算节省 VRAM。否则,您将需要 20GB 的 KV 缓存。
Unsloth 高效 GRPO 算法
我们从 Horace 的 线性交叉熵 实现中获得灵感,并成功应用于 GRPO!我们实际上发现了一些惊人的点:
- 参考 GRPO 实现使用反向 KL 散度,而不是前向 KL 散度。
- 在未正确处理的情况下,用 float16 混合精度(以及 float8)天真的实现线性交叉熵,将会破坏自动混合精度缩放机制。
- 在 GRPO 损失的实现中,我们发现其他怪癖——尤其在反向 KL 散度的公式层面。
💡 GRPO 的数学分析及发现问题
GRPO 首先在 DeepSeek 的数学论文 中于 2024 年 2 月至 2024 年 4 月被引入。随后,在创建 DeepSeek R1 时利用了 GRPO 算法,如他们的论文中所述。我们利用了 Hugging Face 的 TRL GRPO 实现 此处。我们看到 TRL 的实现执行的函数为:
$$L = \frac{1}{n}\sum{\beta D_{\text{KL}}}\big( q ,|, p \big) + A$$
其中我们利用了 反向 KL 散度(而非前向 KL 散度)。Beta 是一个缩放因子,设为 0.04,A 是在考虑所有奖励函数之后的优势。Q 是新的训练好的模型,而 P 是原始参考模型。然后我们注意到有趣的是,该实现计算的反向 KL 散度为:
$$ \begin{align*} p &= \sigma(f(x)) \ q &= \sigma(f'(x)) \ D_{\text{KL}}\big( q ,|, p \big)_i &= \exp(\log(p)-\log(q))-(\log(p)-\log(q)) - 1 \ &= \frac{p}{q} - \log\left(\frac{p}{q}\right) - 1 \end{align*} $$
但这实际上是正确的吗?我们首先尝试推导它,并收集类似项:
$$ \begin{align*} D_{\text{KL}}(q |\ p) &= \sum q \left \frac{p}{q} - \log\left(\frac{p}{q}\right) - 1 \right \ &= \sum q \frac{p}{q} - \sum q \log\left(\frac{p}{q}\right) - \sum q \ &= \sum p - \sum q \log\left(\frac{p}{q}\right) - 1 \ &= 1 - \sum q \log\left(\frac{p}{q}\right) - 1 \ &= - \sum q \log\left(\frac{p}{q}\right) \ &= \sum q \log\left(\frac{q}{p}\right) \end{align*} $$
这意味着实现可能缺少了乘以 Q(新分布项)?但这似乎是正确的,如在创新 GRPO 的 DeepSeek 数学论文在 第 14 页 中 已明确写道。 另外,约翰·舒尔曼 Schulman's 博客 也指出反向 KL 项的不偏估计不需要额外的 Q 项。 我们在博客中看到:
$$ \begin{align*} r &= \frac{p(x)}{q(x)} \ \text{KL}\leftq, p\right &= (r - 1) - \log{r} \ &= \frac{p}{q} - 1 - \log{\frac{p}{q}} \end{align*} $$
我们还发现有趣的地方:
torch.exp(q - q.detach()) * advantages.unsqueeze(1)
被使用,它应该被评估为 1 对吗?
我们实际上发现这是必要的——似乎自动微分引擎可能没有正确传播梯度。因此,我们进行了 4 次实验:
- 通过参考实现进行正常 GRPO(红线)
- 移除分离代码(蓝线)
- 如前所述,带有额外项的完整反向 KL(黄线)
- 改用前向 KL 散度(绿线)

通常,移除分离确实破坏了所有训练,因此我们必须保持在那里——这可能还需要更多研究。似乎所有其他实现看起来都差不多? 我们可能需要长时间运行模型以查看不同的效果。 在所有实现中,我们还采用 logsumexp 技巧:
$$ \begin{align*} \log\sigma(x) &= \log\left(\frac{\exp(x)}{\sum\exp(x)}\right) \ &= x - \log\sum\exp(x) \ &= x - \text{logsumexp}(x) \end{align*} $$
为 GRPO 提供完整日志记录
我们现在还为所有奖励函数提供了完整的日志记录细节! 以前,我们只是展示了总的聚合奖励函数。
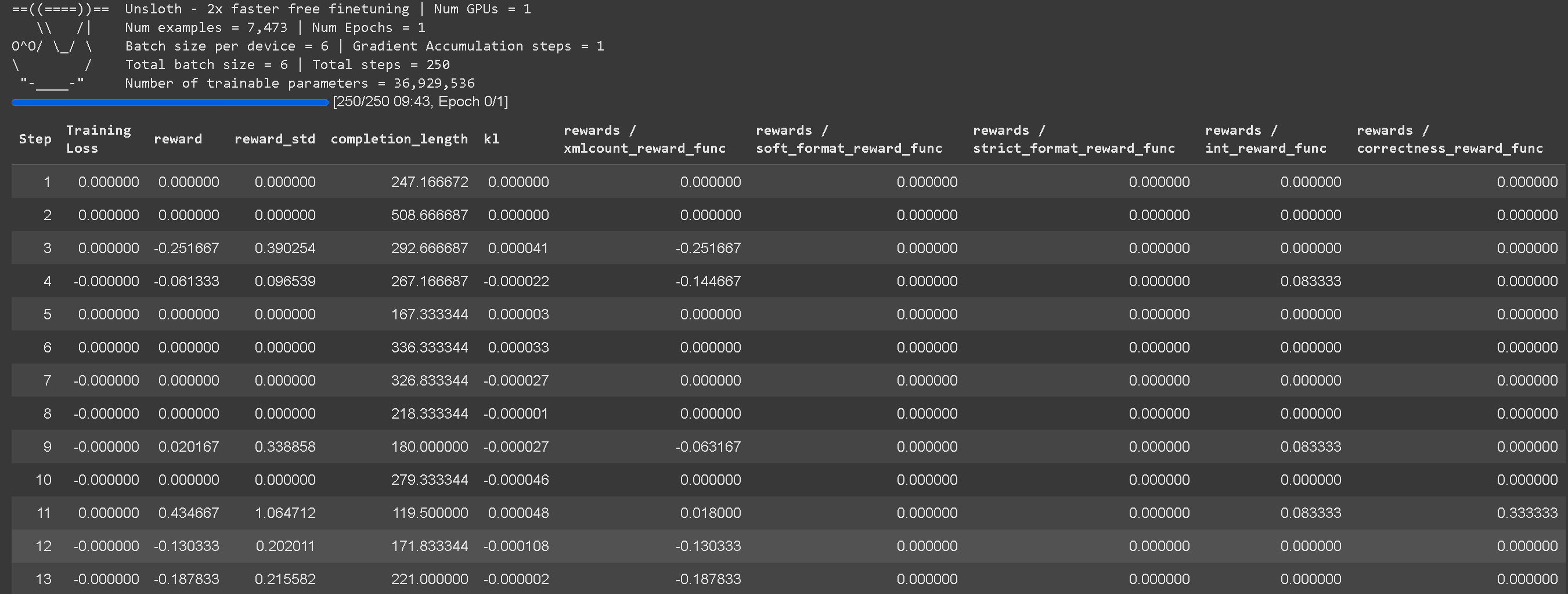
您还不需要调用函数来修补 GRPO!即移除顶部的这个(我们会自动处理):
from unsloth import PatchFastRL
PatchFastRL("GRPO", FastLanguageModel)
vLLM 推理选项
我们现在还允许您为 vLLM 使用 FP8 KV 缓存,这使得在较新的 GPU(RTX 3090,A100 及更新版本)上能够减少 2 倍的 KV 缓存空间使用
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "meta-llama/meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
load_in_4bit = True, # LoRA 16bit 是 False
fast_inference = True, # 启用 vLLM 快速推理
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.6, # 如果内存不足则减少
float8_kv_cache = True, # 启用 float8 KV 缓存
)
如果您希望在 vLLM 中使用 min_p = 0.1 或其他采样参数,我们也支持传递任何 vLLM 的 SamplingParams 参数!
max_prompt_length = 256
from trl import GRPOConfig, GRPOTrainer
from unsloth import vLLMSamplingParams
vllm_sampling_params = vLLMSamplingParams(
min_p = 0.1,
seed = 3407,
...
)
training_args = GRPOConfig(
...
vllm_sampling_params = vllm_sampling_params,
temperature = 1.5,
)
其他更新
🦥 使用 vLLM 直接运行 Unsloth Dynamic 4-bit
你现在可以直接在 vLLM 上运行我们的动态量化并进行推理。这是由于我们在 vLLM 仓库中做出的 接受的 PR。阅读我们动态量化如何在示例和基准测试中显着提高精度,而非标准 4-bit 查看此处。
🚀 运行 Perplexity 的 R1-1776
您现在还可以下载我们的 R1-1776 Dynamic GGUFs,用于 Perplexity AI 的新 R1-1776 模型,这是 DeepSeek-R1 的微调,取消了所有审查,同时保持推理能力。可以在您自己的设备上本地运行它们!
🐱 GitHub Universe 访谈
在 2024 年 10 月的 GitHub Universe,我和 Andrea 进行了一次精彩的访谈,现在视频已经发布!我们会谈到我们从澳大利亚的背景,如何建立 Unsloth,以及所有你们多么令人惊叹等话题!详见 YouTube
感谢!
感谢 Eyera、Edd 和 Keith 又一次帮助我们进行这一版本的发布。非常感谢大家使用和分享 Unsloth——我们真的很感激。🙏一如既往,欢迎加入我们的 Reddit 页面 和 Discord 服务器以获得帮助或展示您对我们的支持!您也可以关注我们的 Twitter 和 新闻通讯。
感谢您的阅读!
Daniel 和 Michael Han 🦥
2025 年 2 月 20 日